
Reading SAS files into Azure Databricks
24 Nov 2020Introduction
Working in an organization where we use so many different technologies, one of my biggest frustrations is working with SAS files (*.sas7dbat). These are relatively easy to read into SQL Server using the SAS ODBC Driver, but the majority of our workloads happen in either Azure Databricks or Azure Synapse. So I was on the lookout for a new and better way to get my data into Azure Databricks.
We can also achieve this with pandas.read_sas however, I wanted to leverage the power of MPP (Massively Parallel Processing). So eventually I found an awesome package created by Forest Fang, but took some fiddling to get this working for me.
Note, you have to mount your storage for this to work, below I have instructions in the links on how to mount Azure Storage. For the pandas and the spark package, you will have to have the storage mounted for it to work.
Prerequisites
- Azure Subscription
- Azure Databricks
- Azure Storage Account Mounted, You can follow this article
Installing the package
When in Azure Databricks, go to your clusters
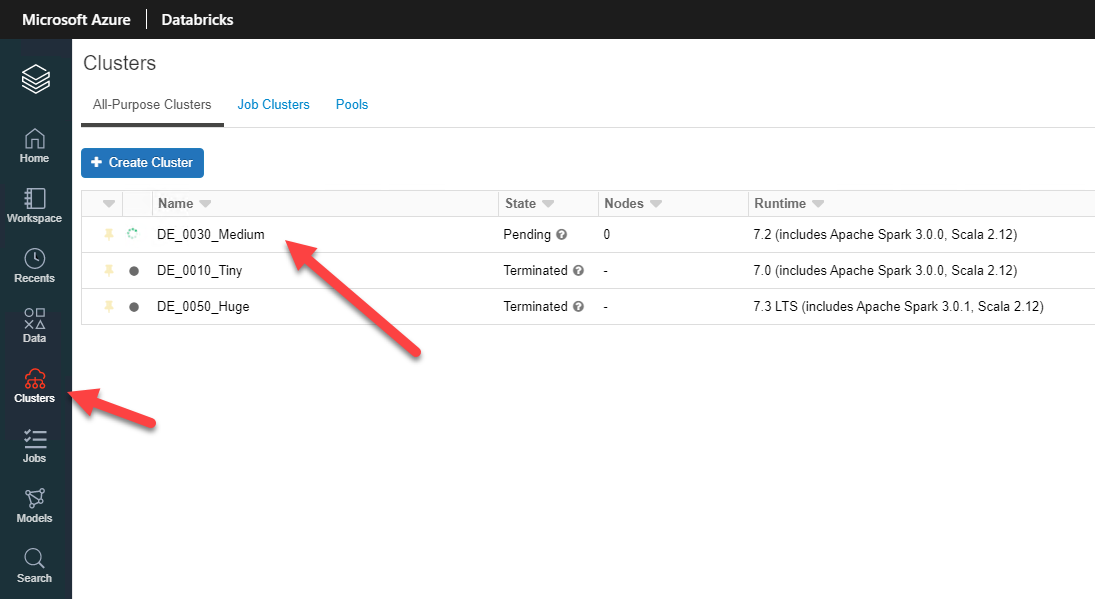
Next go to “Install New”
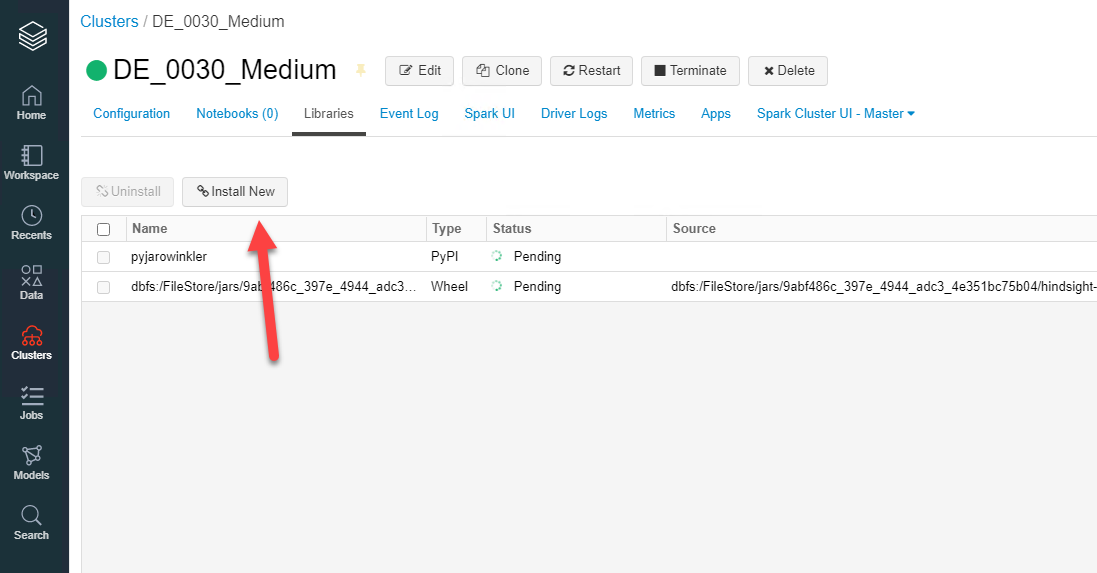
Now go to “Search Packages”
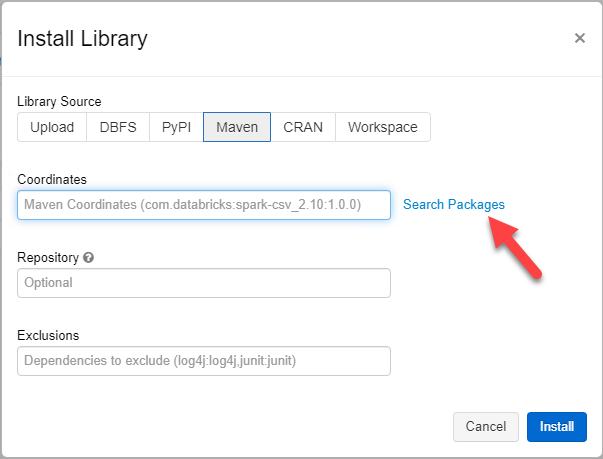
Type “spark-sas7dbat” in the search bar and select the package by saurfang
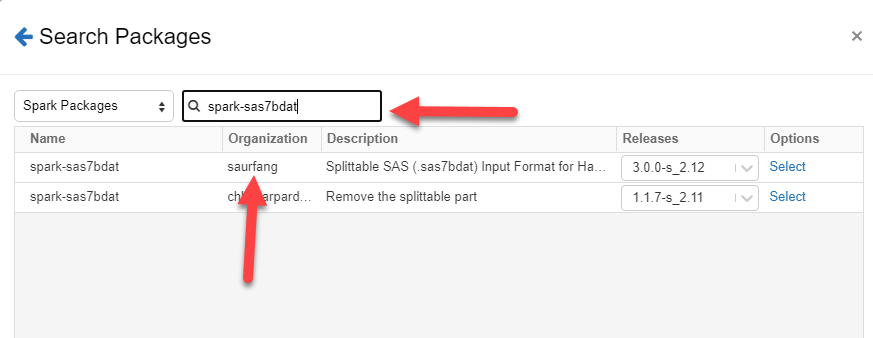
Click the “Install Button”
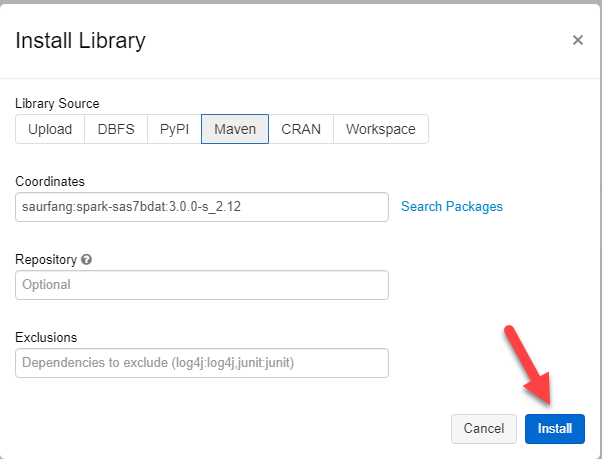
Once the installation complete, please restart your cluster

Code
Now the fun part starts, actually reading our .sas7dbat files into dataframes. Yes you are reading this correctly it is really that simple.
df = spark.read. \
format("com.github.saurfang.sas.spark"). \
load(<Enter the Full Path to your SAS file here>)
For me to save time as I get 100’s of these files at a given time, I wrote the below script to loop though my mounted storage point and import all of the files into a staging area on my Azure Synapse server.
for x in dbutils.fs.ls("/mnt/<ENTER MOUNT POINT HERE>"):
print(x.path)
print(x.name.replace(".sas7bdat",""))
df = spark.read. \
format("com.github.saurfang.sas.spark"). \
load(x.path)
df.write \
.format("com.databricks.spark.sqldw") \
.option("url", jdbc) \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("dbTable", x.name.replace(".sas7bdat","")) \
.option("tempDir", blob) \
.mode("overwrite") \
.save()
for the df.write to work in the above code you will have to configure a few things for the “forwardSparkAzureStorageCredentials” to work, however on a quick work around you can use the below to set the keys in the current session only. You will also require a temporary storage place for Azure Synapse to read the data from, as behind the scenes it use the COPY statement to import the data into Azure Synapse.
For the recommended method please go through this article
spark.conf.set("fs.azure.account.key.<Storage Account Name>.blob.core.windows.net", "<Storage Key>")
jdbc = "jdbc:sqlserver://<SynapseDBServer>.database.windows.net:1433;database=<DATABASE NAME>;user=<USERNAME>@<DATABASE NAME>;password=<PASSWORD>;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;"
blob = "wasbs://<CONTAINER NAME>@<STORAGE ACCOUNT NAME>.blob.core.windows.net/<DIR>"
Final Words
Please do not save passwords and keys in your Notebooks.
Disclaimer: Content is accurate at the time of publication, however updates and new additions happen frequently which could change the accuracy or relevance. Please keep this in mind when using my content as guidelines. Please always test in a testing or development environment, I do not accept any liability for damages caused by this content.
If you liked this post, you can share it with your followers or follow me on Twitter!